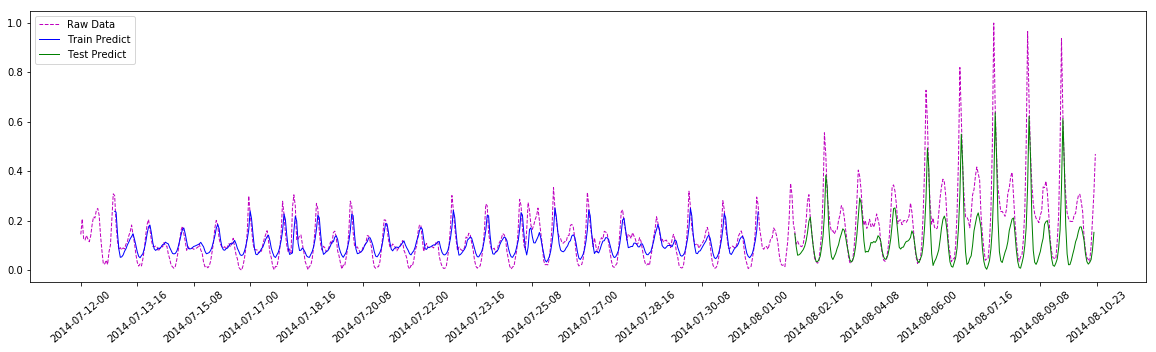
本次命题: 数值预测 上一篇文章我们的小题目是使用LSTM预测字符顺序的下一个字符。 命题虽然简单, 可是实际上应用范围也很广。 比如输入法里面, 就一定会用到相关的技术。 只不过不一定是LSTM, 肯定也不止一维特征。这次这个命题相对来说, 比较实际一些:从历史预测监控数据预测即将来临的监控指标的数值。 比如下图就是本站在友盟上面的监控数据。 最右边的虚线部分就是友盟进行的预测的数值: 本文代码特别鸣谢:https://blog.csdn.net/aliceyangxi1987/article/details/7…

之前尝试使用Spark MLlib 做机器学习,发现不是非常方便,也可能是在使用习惯上面不太适应(相对 python sklearn). 今天尝试使用Spark MLlib 针对Iris数据做一次实践,之后会尝试写一个包装类,将这些步骤简化。 0. 数据准备: 原始的数据以及相应的说明可以到[这里] 下载。 我在这基础之上,增加了header信息。 下载:https://pan.baidu.com/s/1c2d0hpA 如果是可以直接从NFS或者HDFS之类的文件服务里面读csv,会比较方便, 参考下…

0. 引言 上周五在公司使用gensim的word2vec实验了一次“文档相似性”计算。匹配出来的结果惨不忍睹,可以用“天马行空”来形容。这就是对word2vec不了解的情况下做调包侠的下场。。。 下面是笔者对word2vec的一些初步了解与效果反思。 本文为原创。 转载需要注明出处:http://www.flyml.net/2016/11/07/word2vec-basic-understanding/ 1. 为什么学习w2v? 简单的说,我们在声音与图像领域,深度学习都取得了令人瞩目的成就,其中一个重要的原因,…

今天发现Kaggle上有一个新的机器学习比赛,主题是RedHat 用户商业价值预测。 参赛地址: https://www.kaggle.com/c/predicting-red-hat-business-value 比赛还剩24天,差不多过了一半。后面如果实力足够,还是有机会拿奖。 奖金一共5W美刀!按照现在差不多1:6.6的比例来计算,差不多有33W人民币呢! 而且这次比赛的数据量也不是很大,单机基本上就可以搞定。 File Name Available Formats people.csv .zi…