原创声明: 本文为原创文章,转载需要注明来自http://www.flyml.net 为了更好的阅读体验,请回源站查看文章。有任何修改、订正只会在源站体现 最后更新时间:2016年09月03日

原创声明: 本文为原创文章 为了更好的阅读体验,请回源站查看文章。有任何修改、订正只会在源站体现 最后更新时间:2016年09月02日

原创声明: 本文为原创文章 如需转载需要在文章最开始显示本文原始链接 为了更好的阅读体验,请回源站查看文章。有任何修改、订正只会在源站体现 最后更新时间:2016年08月28日
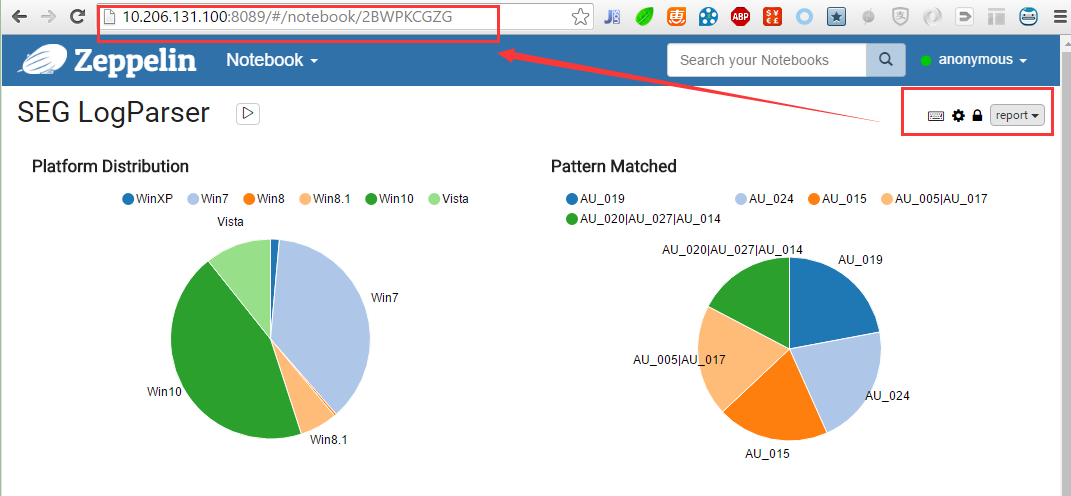
原创声明: 本文为原创文章 如需转载需要在文章最开始显示本文原始链接 为了更好的阅读体验,请回源站查看文章。有任何修改、订正只会在源站体现 最后更新时间:2016年08月24日
原创声明: 本文为原创文章 如需转载需要在文章最开始显示本文原始链接 为了更好的阅读体验,请回源站查看文章。有任何修改、订正只会在源站体现 最后更新时间:2016年08月24日
原创声明: 本文为原创文章 如需转载需要在文章最开始显示本文原始链接 为了更好的阅读体验,请回源站查看文章。有任何修改、订正只会在源站体现
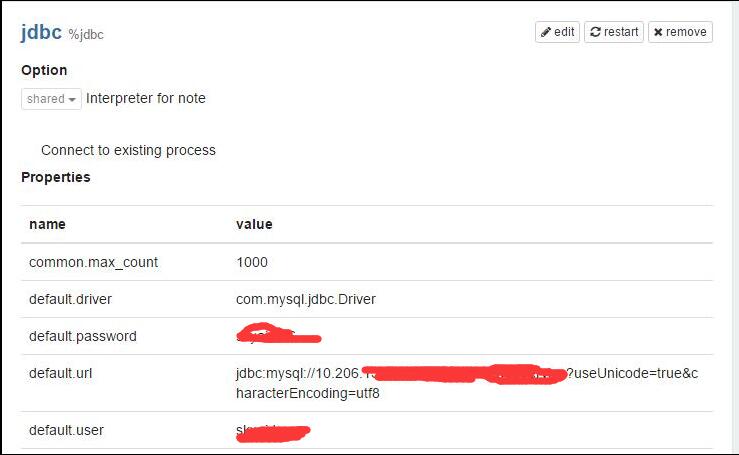
原创声明: 本文为原创文章 如需转载需要在文章最开始显示本文原始链接 为了更好的阅读体验,请回源站查看文章。有任何修改、订正只会在源站体现

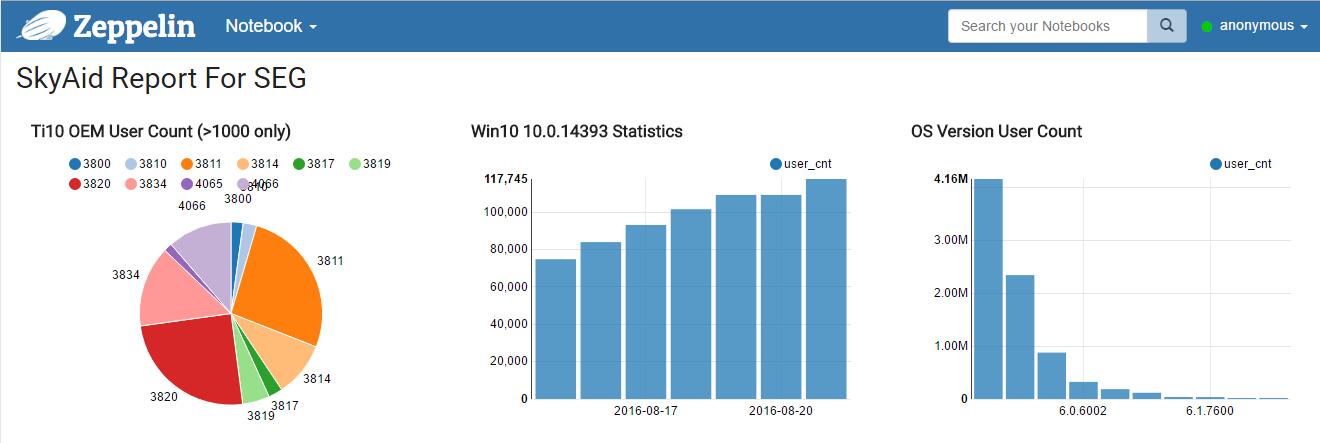
0. 简介 Spark 是一个非常好的计算平台,支持多种语言,同时基于内存的计算速度也非常快。整个开源社区也很活跃。 但是Spark在易用性上面还是有一些美中不足。 对于刚接触的人来说,上手以及环境搭建还是有一些困难。 另外,如果希望将结果绘制成图表分享给别人,还需要很长一段路程。 目前已经有一些解决方案: 【TBD】Jupyter Notebook 使用很广泛,但是看起来主要还是以前ipython-notebook的增强版。 目前笔者对其了解不多 Spark 母公司DataBricks提供的DataBricks …
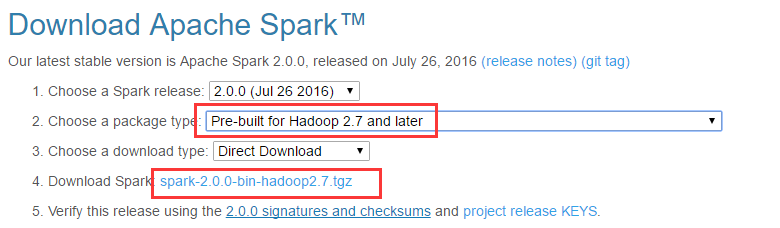
在学习Spark的时候,当然可以搞一个单机的Spark集群。 在写代码的时候,自然没有什么太大的问题了。但是是不是总有一种意犹未尽、隔靴骚扰的感觉? 如果你的答案是否,好吧,你可以关闭此页了。 首先,有一个新人经常遇到的问题: Spark集群是否一定需要Hadoop集群呢? 答案是否。 Spark的集群一共分3种: Standalone Hadoop-Yarn Mesos 今天我们主要涉及的就是Standalone这种模式。在这种模式之下,我们完全可以使用NFS来代替Hadoop / HDFS. 并且…