原创声明:
- 本文为原创文章
- 为了更好的阅读体验,请回源站查看文章。有任何修改、订正只会在源站体现
- 最后更新时间:2016年09月02日
Cassandra 简介
- Facebook 产生,并且一开始用来存放“收件箱”, 后来貌似迁移到HBase并将其捐献给Apache, 但是收购的Instagram从Redis迁移到了Cassandra
- 设计思想结合了AWS的DynamoDB + Google BigTable
- 分布式的NoSQL 数据库
- Write > Read. 大多数数据库的都是写优化, 而Cassandra的写性能大于读性能
- 时间序列数据库大爱
- 很多世界级的公司 and 大公司都在使用:
- Apple / Netflix / Samsung / eBay ...
- Intuit / Reddit ...
http://www.flyml.net
优点介绍
Cassandra具有常见NoSQL 分布式数据库 的优点, 但是值得一提的是:
- 去中心化
- 虽然没有完全去除,可以设置多个“中心”
- 但是该“中心” 实际上并没有太特殊的功能
- 这一点跟Hadoop based的HBase / Hive 很不一样
- 容易使用
- 安装、维护、升级都相对比较简单
- 自带的命令行工具也比较强大
- 如果是Enterprise版本,还有很强大而人性化的Web管理界面
- 连Windows机器都可以安装一个集群并且性能方面还不错
- 兼容大部分SQL语法
- 比如MongoDB 、 HBase 在使用习惯方面,对于熟悉RDBMS的人来说就要差太远了
http://www.flyml.net
关于性能:
任何一个厂家都会说自己的DB性能是XX的10x,甚至100x。但是实际使用上面,可能完全体现不出来~ 原因很多,比如厂家虚报成绩、特殊的测试场景。下面使我们的真实数据:
- 每天40-50G数据
- 8000W条插入 + 400W读
- 8台机器, 10分钟
- 全表扫描(200G) + 统计计算: (Spark)
- 10-15分钟
- 按照主键查询:
- 10-20 ms 级别
使用上完全满足了我们的需求。
PS: 笔者并没有对其他数据库做实际的性能测试,因此有可能采用其他的数据库表现会更好一些
生态环境:
一个好的产品,除了自己牛逼,还要搭建一整套生态环境,至少融入到一个大环境之中。我觉得Cassandra让我很开心的一点就是融入到了Spark 这个欣欣向荣的大生态之中。可以非常轻松的集成Spark来做统计分析,同时跟一个(个人认为)非常有潜力的Zeppelin轻松集成。
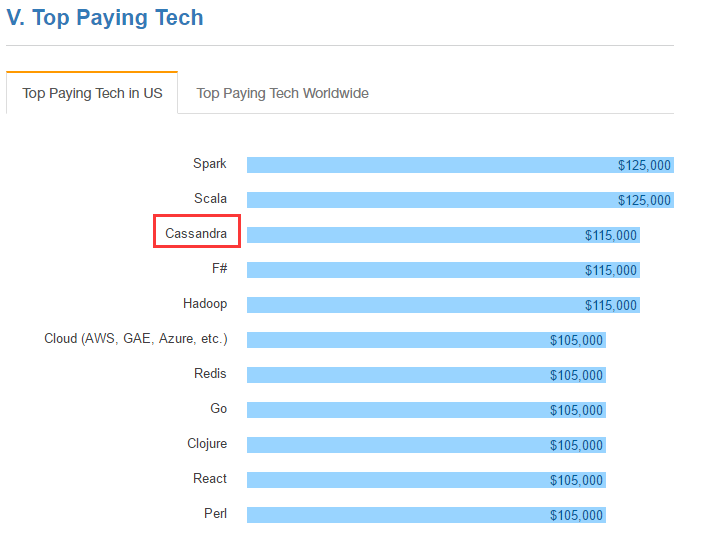
分享数据:IT工资排名
数据来源: http://stackoverflow.com/research/developer-survey-2016#technology-top-paying-tech 数据显示Cassandra也是很有钱景的一个工具
美国最值钱技术排行
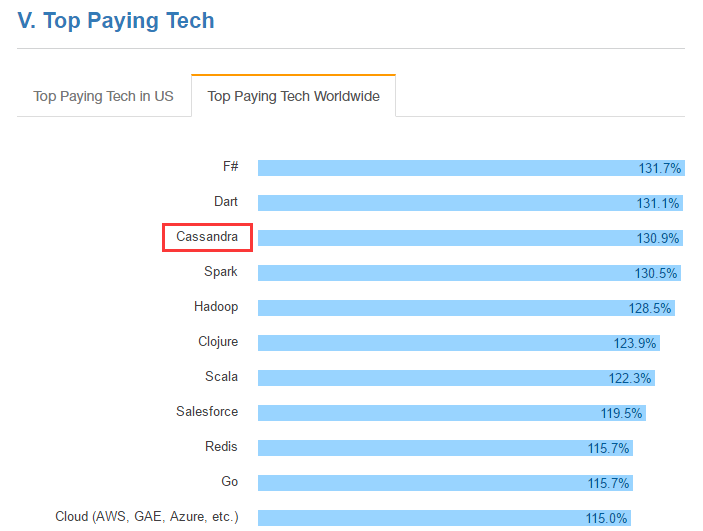
全球最值钱技术排行
上面说了不少Cassandra的好话,可能你要说我连听都没听过。。。
不过在国内,Cassandra用的公司确实很少,无论是从百度指数还是拉钩上面爬下来的数据显示,Cassandra的用户非常少,Hive 、 HBase 要多非常多。 可能这个跟实际的使用场景有关。
注意: Cassandra毕竟还只是一个数据库,并不完全适合批处理
如果你需要一个分布式的实时数据库,同时又要求这个数据库方便的做数据分析(而不是另外创建数据仓库),我相信Cassandra绝对是一个值得考虑的选项!
下面分享一些真实的Cassandra相关的数据, 数据显示:Cassandra在国外的受众还是挺广泛的
分享数据:GitHub 数据
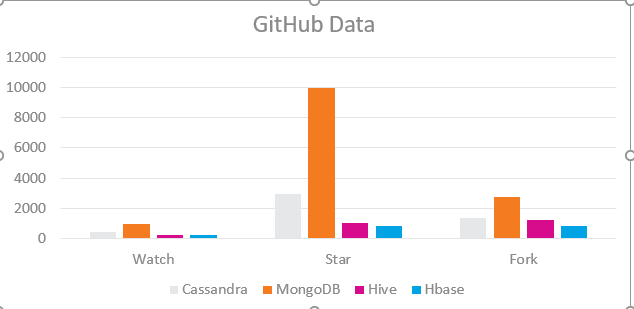
可以看到,MongoDB 独领风骚,关注度、使用人数都非常非常多。 但是接下来的第二名Cassandra基本上就完全压制了Hive / HBase。
只不过我们的业务场景,确实不太适合MongoDB,再加上不断有人在反馈当数据量非常大的时候,MongoDB开始莫名其妙的丢数据,也就敬而远之
分享数据:Google Trend 数据
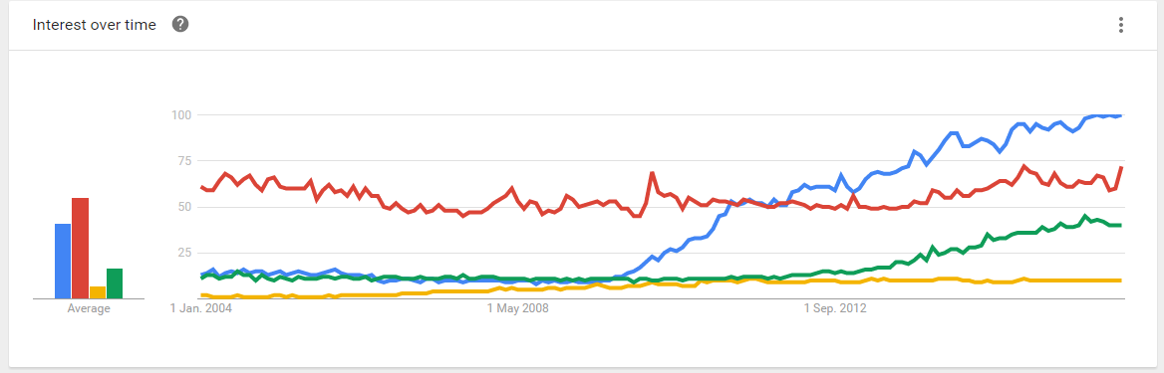
其中:MongoDB Apache Cassandra HBase Hive
整体情况跟GitHub 上面的数据完全一致。 只不过我们看到Hive最近上升的速度非常明显!值得关注~
http://www.flyml.net
结论:
其实在这里并不是忽悠大家一起去用Cassandra。 只是看到国内对Cassandra的使用太少,而自己觉得Cassandra 是一个很不错的数据库,并且Cassandra在国外的应用还是非常广, 我相信它值得大家花时间来了解了解, 甚至搭建一些测试环境来进行一些概念验证或者技术研究
我们的团队之所以最终选择了Cassandra,是综合考虑了数据库的各个方面的特性,并结合自己团队以及业务的特点来做得最终选择。并且性能并不是我们的最重要的因素。
http://www.flyml.net
如果您确实有兴趣来尝试Cassandra,可以看下一篇《Cassandra的安装、升级与集群维护》
敬请期待
本文为原创文章,转载请注明出处:http://www.flyml.net


文章评论
你好,10台服务器,128G内存,怎么架构可以达到每秒20万的入库速度?
默认架构,并没有特殊处理, 只是因为数据全是内网导入.
同时Cassandra 默认一开始会写到内存, Log 是append的方式. 同时,之前的机器是双硬盘
如果Log 所在的硬盘是SSD 还能更快一些
rangerwolf 你好,我们公司最近要要上 cassandra + kafka 的项目, 但是惮于公司技术能力不够运维cassandra, 所以想问下,你们有能力帮助运维吗?
“Write > Read. 大多数数据库的都是写优化, 而Cassandra的写性能大于读性能”
应该大多数数据库(sql)都是读优化吧,按照你这里的描述逻辑,这里描述错误了吧。
这里的问题不大,这就是这种机制的问题。
首先,写入的时候,都是append only的方式。这种方式写入是非常快的。 无论是插入新增还是修改, 直接无脑写入。
其次,读的时候就需要读几个地方。 即使对于相同的记录, 可能还需要全部都读一次,找出最后的那一条记录才能返回结果。
收购的Instagram从Redis迁移到了Cassandra,知道是为什么吗?
不好意思, 不太清楚