引言 翻了一下以前写的Cassandra相关的教程, 发现最开始是2016年写的博客了. 也没想到坚持了这么久. 经过这么长一段时间使用Cassandra作为基础数据承载的基础架构, 有一些实战获得的经验. 总而言之, Cassandra并不适合类似金融方向这种需要高可靠性\事务性的业务. 但是对数据分析, 确实有一些功能比较好用. 省心的重复数据处理 在批量导入数据到数据库之中的时候, 难免有重复导入的时候. 如果使用MySQL等等, 就需要事先按照时间或者其他条件, 先把历史数据删除. 而Cassandra并不…

使用docker的方式部署Cassandra节点 优点 使用Docker 可以更快速的解决很多环境配置问题: 不需要实现安装java 不需要配置supervisor (使用docker来管理进程) 不需要去配置ulimit 等等文件最大数配置(镜像里面已经配置好) 可以直接在命令行修改相应的配置 更新新的版本 相比之前也容易很多. 缺点: 这种方式, 没有办法充分利用双硬盘 部署步骤: 因为是一次性的事情, 所以没有使用Python Paramiko之类的方式远程执行SSH命令 人工登录目标机器 登录docker …
这一篇文章, 主要讲的是如何优化python client的性能, 不是Cassandra本身的性能优化. Cassandra本身的性能优化, 主要是对DB Schema的设计上面的优化. 那python client 为什么需要优化呢? 正在进行的一个项目就遇到这种情况, 无论如何优化, 性能就是无法提升. 一直维持在2000条/s的水平. 这个时候发现: 1. 只使用了单核cpu 2. 这一颗CPU已经100% 官方其实已经有一些关于性能优化的建议与文章, 但是感觉有的并不实用. 作者根据自己的实际操作的经验,…
Zepplin 前段时间发布了0.7.0新版本, 在尝鲜的同时, 也在尝试将Zeppelin + Cassandra组合起来使用。 根据官方文档, Cassandra Interpreter 还是做了不少事情的, 说不定比windows版本自带的DevCenter更加好用。 但是在使用之前, 首先得解决Guava冲突的问题。 因为尝试了很多,具体哪一步起作用也不记得了, 下面三部最好都做: 将$ZEPPELIN_HOME/lib 里面的guava-15.0.jar 替换成guava-16.0.1.jar 如果$ZE…
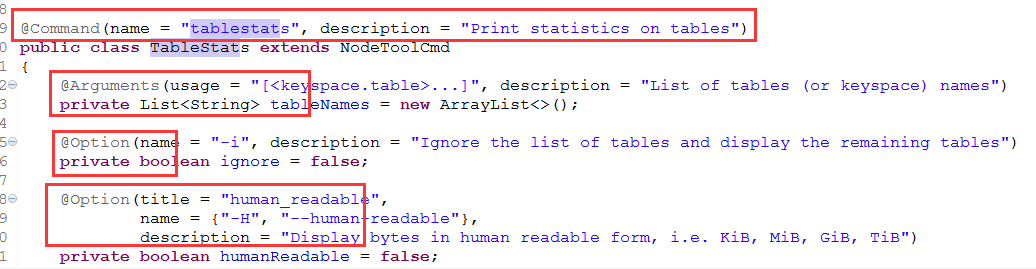
在之前的文章《使用nodetool 进行监控之初步使用》我们提到,新版本的Cassandra Nodetool 支持了 --format / -F 这个参数,可以将内容输出成json或者yaml格式。那么具体是如何实现的呢? 本篇文章的目的就是尝试来阅读以下具体实现的源码。 从哪里入手? 首先https://issues.apache.org/jira/browse/CASSANDRA-5977 。在这个issue之中,附带了patch的实现。从path之中,可以看到commitor首先修改了TableStats的…
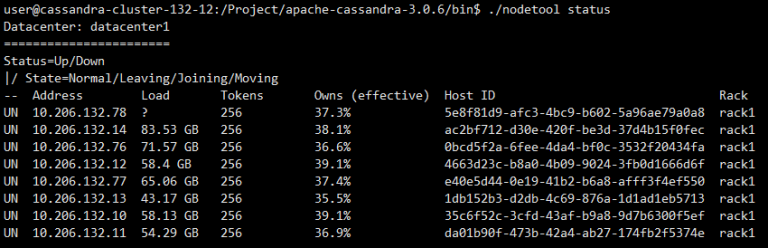
之前的文章《Cassandra自带工具》提到了nodetool的使用,不过当时讲得并不够深入。这篇文章针对监控方向进行一些更深入的介绍。 同时,如果你正好跟我一样没法切换到Enterprise Edition,用好nodetool成为做好Cassandra监控的第一步。 nodetool status 这个命令在之前的文章已经有所介绍。这个是最常用的命令,可以非常明了的看到整个集群的状态。 当你的集群节点不是非常大的时候,使用这个命令非常方便。 nodetool info 查看当前节点的…
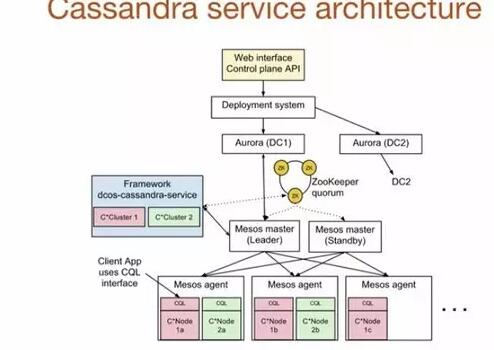
原文链接: http://mp.weixin.qq.com/s/xJhm35IXm_sAPLJ86OwTFA 要点总结: Cassandra运行在Mesos容器之中。使用Mesos在读写延迟上面的影响约在5~10% 写延迟:在裸服务器上平均是0.43ms,而Mesos上是0.48ms。 读延迟:在裸服务器上平均是0.38ms,而在Mesos上是0.44ms。 使用Mesos的好处是,可以面向数据中心的资源编程,控制上要灵活很多 一共2个数据中心,东西海岸各一个,每个300台机器 里面又细分了20个小的集群,这样资源…

昨天有个同事遇到数据库方面的问题: 他用PostgreSQL记录用户的App的数据,比如一个用户装了100个App,那么在DB之中就有100条记录。当前产品一共有150W这样的用户,那么总共数据集在1.5亿,另外他们使用了uuid-app_name+app_version 三个值作为组合主键,总共约有5亿条记录。 首先他们创建索引之后,每次插入都很慢,另外查询的时候,即使只是按照uuid进行查询,因为数量级已经超过postgreSQL索引的最大容量,只能很麻烦的另外安装插件,通过模糊搜索的方式进行数据…

我们知道,Cassandra这种NoSQL数据库,天生无法执行join的操作。 但是如果你手上刚好有一个Spark集群,那么就方便很多了。我们可以在Spark SQL之中进行join的操作。 本文基于Spark 2.x 进行操作。2.0以后,我们不再需要单独的定义JavaSparkContext / SparkConf 等对象,只需直接定义一个SparkSession即可。同时我们可以统一使用Dataset来对数据进行操作,在易用性、性能上面都很不错。 下面是链接Spark与Cassandra的相关代码: [cra…

对Cassandra的架构做了一些了解,没有深入代码级别,有一些细枝末节也没有完全摸清楚。不过在大致流程上,基本上理解。在此做个阶段性的小结。 具体请看PDF 本文为原创文章,转载请注明出处 原文链接:http://www.flyml.net/2016/11/07/cassandra-tutorial-architecture/