原创声明:
0. 简介:
上一篇文章《让Spark如虎添翼的Zeppelin – 基础篇》 我们演示了如何搭建一个最基本的Zeppelin。
现在我们将小试牛刀,使用Zeppelin来快速展示MySQL的数据。
MySQL通常作为我们ETL之后的数据存储媒介。 MySQL本身的功能很完整,使用也很方便,就是在最后一步数据展示上面,并没有很好的解决方案。
我们当然可以使用Tableau等软件进行非常绚丽的展示,我们也可以使用Python + Matplotlib 等自行编程解决数据展示的问题。
但是现在我们已经有了Zeppelin,他也是快速数据展现的一个好手
1. 配置Zeppelin使其支持MySQL
Zeppelin原生支持JDBC链接。 但是默认的设置是指向PostgreSQL.
一种最简单的办法就是直接修改JDBC Interpreter里面的内容,指向你自己的MySQL实例即可。如下图演示:
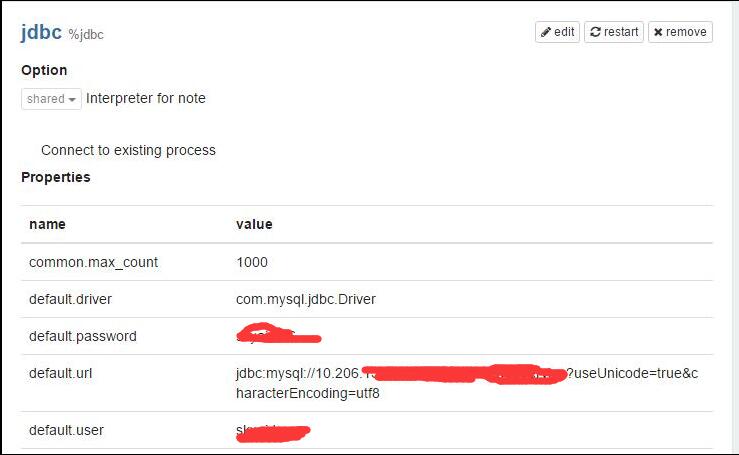
需要设置的有:
- default.user
- default.password
- default.url
- default.driver
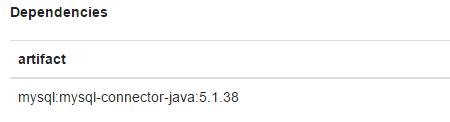
另外需要注意的是,需要增加MySQL的JDBC artifict。 笔者使用的是:mysql:mysql-connector-java:5.1.38
以上配置好了之后,restart interpreter 使得配置生效即可
2. 小试牛刀
新创建一个NoteBook, 比如叫做 Daily Report,并且确认一下jdbc interpreter已经确认使用。(确认方法参考上一篇文章)
之后就可以调用%jdbc 编写SQL并将结果展示出来了。
比如:
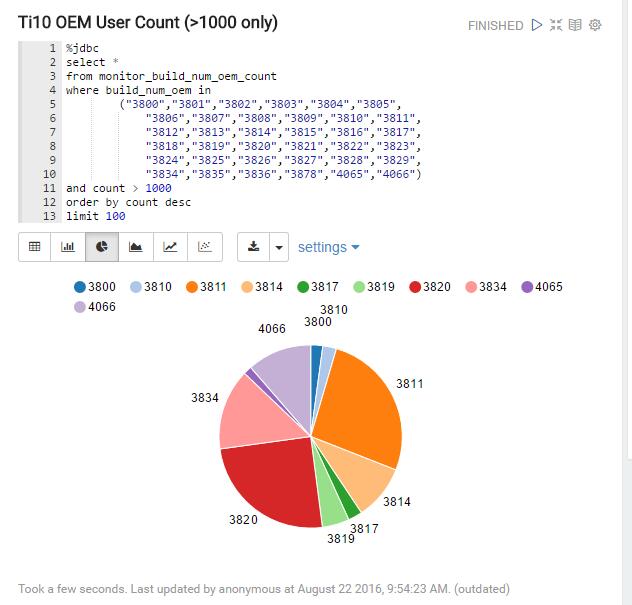
在这里面我们可以写SQL并将数据用饼图的方式来展现。 同时我们还可以设置一个Title
另外,我们可以将整个作为一个report 分享给其他项目组的同事, 只需要选择下面的“report”选项
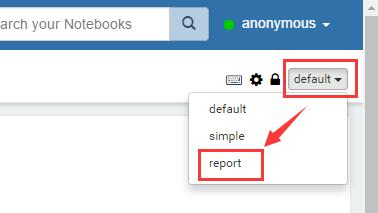
也可以直接将某一个paragraph分享出去(可以自己做一个页面集成需要的paragraph)
3. 绕过的一些坑
不得不说的是Zeppelin还是不够稳定,还是有一些坑存在。 并且目前笔者并没有办法填平,只能绕过去
3.1 创建单独的mysql interpreter 失败
笔者曾经尝试创建单独的MySQL Interpreter. 但是一直会遇到各种错误,比如:
- prefix not found
- interpreter not found
等等。
绕过去的方案:直接修改JDBC而不是自行新建
3.2 莫名其妙的需要我Login
Zeppelin默认是向0.0.0.0 开发的,并且默认是匿名访问。
但是有时候Zeppelin一些错误配置之后,即使将配置恢复回来也没法恢复,还是需要我登录。 问题是我完全没有设置过账号密码。。。
绕过去的方案: 重启Zeppelin --> 重启机器 --> 重头配置
上面三个方案,一个个的试试看 T_T
3.3 展现的柱状图,X坐标自己自动排序
也就是说,展示的x坐标的内容的顺序,不是按照我们给出的值的顺序。
这个问题在0.6.1 上面也并没有解决。 在GitHub 上面已经有人给出了PR,但是因为有冲突,一直没有被合并进去。
出现问题的图如下:
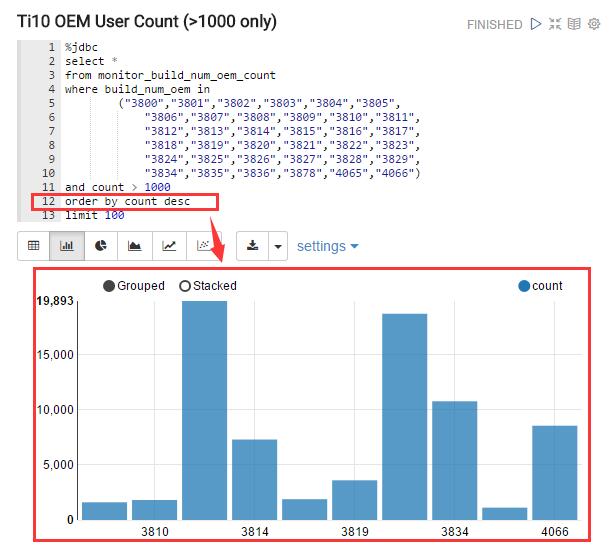
可以看到,我在SQL之中已经强制了 order by count desc, 就是希望展示出来的图表能够按照人数进行降序排序。 但是结果是会自动按照key(build_num_oem)进行自动排序。
其原因是:Zeppelin在将数据喂给Pivort.js 进行数据展示的json,没有考虑到顺序。 需要另外增加一个Index 来解决
具体可以参考: https://github.com/apache/zeppelin/pull/83
绕过去的方案: 说服你的客户这个问题会在将来的不久被解决掉
4. 总结:
Zeppelin是一个非常有潜力的项目。 目前已经能帮助小型团队解决了不少问题。
但是主要的问题还是稳定性。
希望Zeppelin能长久的完善下去
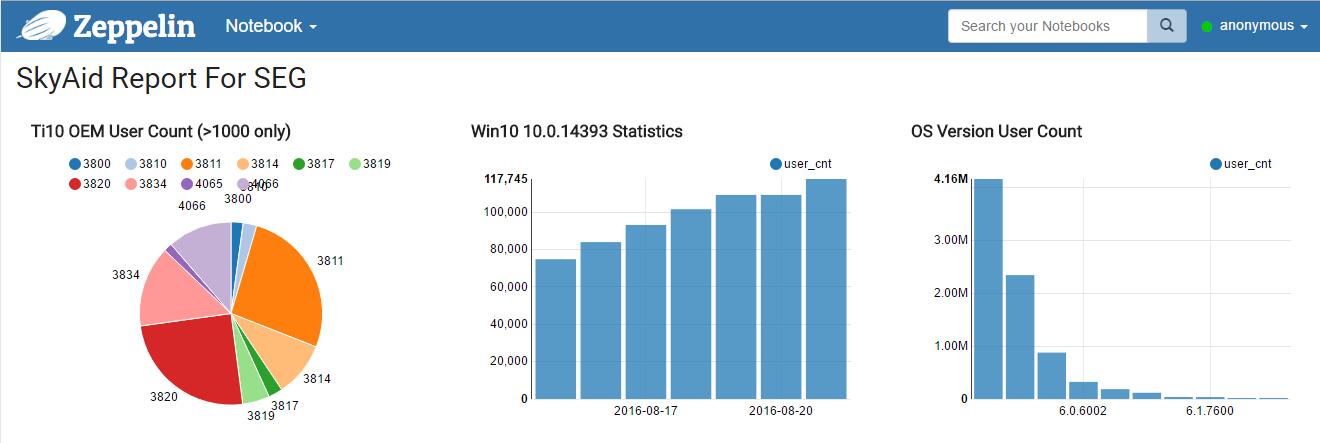
最后放一张完成之后的效果图:


文章评论