本文主要内容参考Spark Summit 2016 & 2015 的油管视频
如果您能直接听懂英语,建议直接观看视频。 视频连接已经添加到文末
如果您无法穿墙,也可以下载Slides:
链接: https://pan.baidu.com/s/1kVllFgj 密码: k4uf
原文作者:Holden Karau 请用She/Her来称呼Ta
请不要小看此人,此人已经出了不少Spark的书啦!

为什么pyspark会慢?
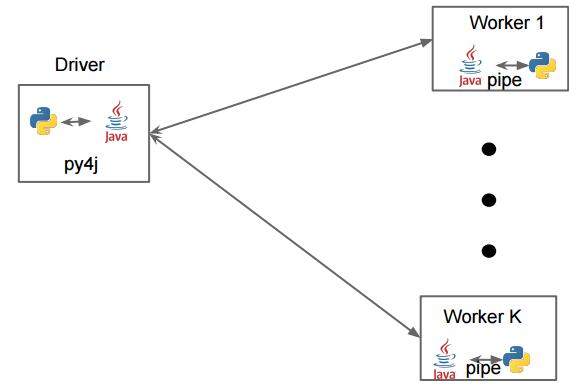
参考上面的图,可以看到,
- Driver: 需要将对象、内容序列化传递给jvm / scala 线程
- Worker: 将scala / jvm 之中的内容反序列化传递给python code
也就是说,一共进行了两次系列化操作, 这是pyspark慢的最主要的原因,并且也是pyspark最大的问题。
pyspark还有一些其他的问题
比如:
- pyspark的启动时间比scala / java 要慢一些
- python 的内存管理在JVM之外,如果spark部署在Yarn之上,那么很容易因为python 解释器与JVM在争抢资源而使得worker / executor 挂掉
- python的错误信息不太好debug,
- 比如python的异常信息是对scala / jvm的异常信息的包装, 中间隔了一层,可能就不太好debug了
避免使用groupByKey / sortByKey
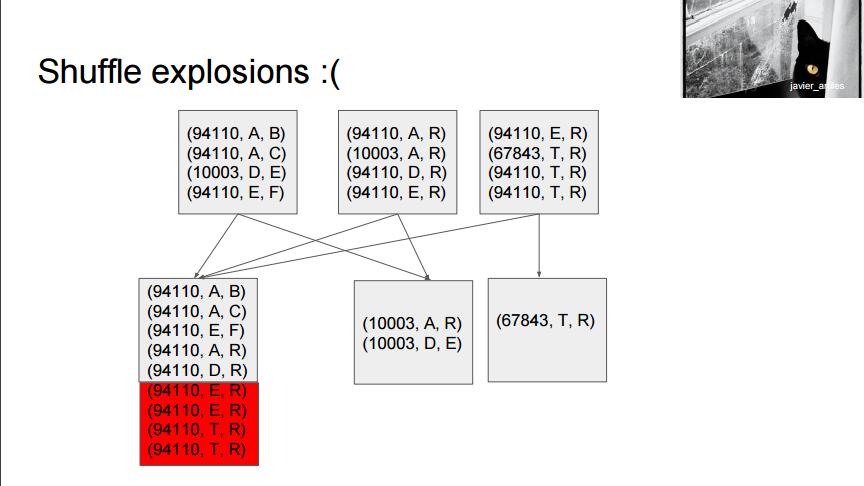
groupByKey的主要问题是,通常我们的数据都是非常倾斜的, 比如统计软件安装数量,Google chrome 这个group的长度就会非常非常大, 而另外一个不知名的小软件,可能就只有Google Chrome的万分之一。 在这种场景之下,如果我们使用groupByKey, 会使得我们的partition非常的不平均。 当一个partition 超过单机内存的极限的时候,会导致整个job失败!
同时,另外一个groupByKey 造成的巨大问题就是Shuffling
所谓Shuffling, 简单的说就是数据在各个worker之间传递。
那么不用groupByKey, 用什么呢? 这里有两个选择:
- reduceByKey
- 比如官网提供的word count 例子,用的就是reduceByKey
- 根据Video / Slides 之中的对比,groupByKey的执行时间是400ms, shuffle size : 48KB, 而reduceByKey 分别是16ms / 11KB
- aggreateByKey
上面两个API的使用案例与说明,可以参考本站的另外一篇文章:《Spark入门: 3种WordCount的实现方式》
SortByKey 会造成跟groupByKey 非常类似的问题:
- Shuffle 太多
- 将相同Key的数据放在同一个partition,容易导致job失败 (大约 2GB)
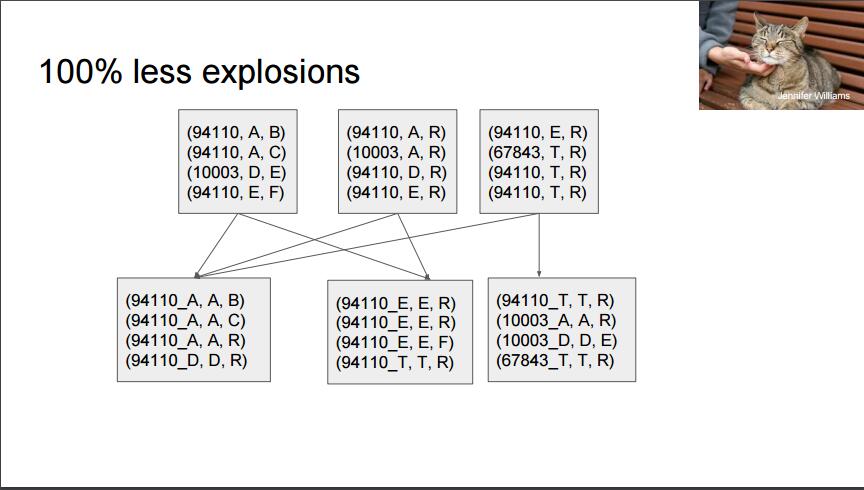
解决数据倾斜的一种方法:Key Hash
(这是我自己想出来的名字,不知道有没有更专业的名词)
举个栗子:
目标:我们需要统计软件的安装数量。
已有数据: user_id (比如 00001, 00002 ...) , software_name (Google Chrome / Firefox ...)
原始方案:(software_name , user_id)
比如 (Google Chrome, 00001), (Google Chrome, 00002),(Google Chrome, 00010) ... , (Fire fox, 00010), (Fire fox, 00011), ...
改进方案:(software_name_odd, user_id), (software_name_even, user_id)
这样 Google Chrome 就会被分成两个partition: Google Chrome_odd, Google Chrome_even
虽然partition的数量变多了,但是保证了整体job的稳定性。
放两张slides的截图做说明:
拯救者: DataFrame
注意: 这是Spark的DataFrame ,而不是R或者pandas 里面的DataFrame。 Spark毕竟是一个分布式的计算平台, 至少目前DataFrame的能力跟pandas之中的DataFrame的能力完全不是一个级别的。 但是唯一的优点就是:快
世上没有银弹,既然需要分布式的能力,就只能拥抱一些限制 :D
最后来一张图片,说明一下DataFrame的速度
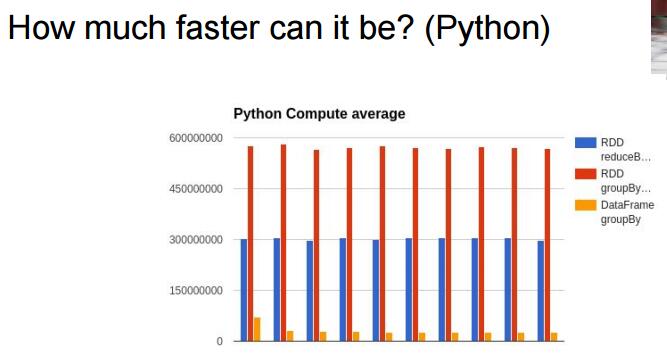
Buuut! 请不要使用UDF, 不然还是会产生两次序列化的操作,降低性能!
原始的Slides包含了更多的内容,推荐下载仔细学习。
没看懂的一页:RDD re-use - sadly not magic
Spark Summit 2016 Video:
https://www.youtube.com/watch?v=V6DkTVvy9vk


文章评论