整体来说,2016高开低走,建树寥寥~ 所谓高开,是指上半年势头不错,并且我在公司也升了一级,加薪幅度也还可以~ 下半年就是各种不给力跟失败了~ 下面一个一个主要项目过一下~ (1) 在线考试系统 从2015年11月启动,到2016年上半年基本完成。这之中投入了不少时间与精力,到了这两天终于有消息,貌似可以有客户。 希望2017年能真正的开始赚钱,也不在乎多或者少,希望慢慢长大变强,成为一个稳定的资金来源 (2)SkyAidWebService 上半年项目组3个人,黄金搭档。做了不少…
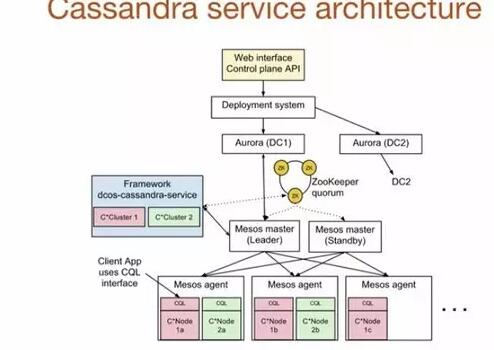
原文链接: http://mp.weixin.qq.com/s/xJhm35IXm_sAPLJ86OwTFA 要点总结: Cassandra运行在Mesos容器之中。使用Mesos在读写延迟上面的影响约在5~10% 写延迟:在裸服务器上平均是0.43ms,而Mesos上是0.48ms。 读延迟:在裸服务器上平均是0.38ms,而在Mesos上是0.44ms。 使用Mesos的好处是,可以面向数据中心的资源编程,控制上要灵活很多 一共2个数据中心,东西海岸各一个,每个300台机器 里面又细分了20个小的集群,这样资源…

昨天有个同事遇到数据库方面的问题: 他用PostgreSQL记录用户的App的数据,比如一个用户装了100个App,那么在DB之中就有100条记录。当前产品一共有150W这样的用户,那么总共数据集在1.5亿,另外他们使用了uuid-app_name+app_version 三个值作为组合主键,总共约有5亿条记录。 首先他们创建索引之后,每次插入都很慢,另外查询的时候,即使只是按照uuid进行查询,因为数量级已经超过postgreSQL索引的最大容量,只能很麻烦的另外安装插件,通过模糊搜索的方式进行数据…

我们知道,Cassandra这种NoSQL数据库,天生无法执行join的操作。 但是如果你手上刚好有一个Spark集群,那么就方便很多了。我们可以在Spark SQL之中进行join的操作。 本文基于Spark 2.x 进行操作。2.0以后,我们不再需要单独的定义JavaSparkContext / SparkConf 等对象,只需直接定义一个SparkSession即可。同时我们可以统一使用Dataset来对数据进行操作,在易用性、性能上面都很不错。 下面是链接Spark与Cassandra的相关代码: [cra…

在python之中,读文件是一个很简单的事情。 直接 open("filename")就可以了。但是python2之中对CJK三种语言却处理得很蛋疼。 特别是在读取CJK语言的文件的时候,一种比较保险的强制使用某种编码的方法是使用codecs类库。 比如: [crayon-68756c959e4ff138689228/] 否则,可能出现一些奇奇怪怪的错误~