引言 最近使用MySQL做一些数据统计比较多。 有时候为了省事直接写出了一个略复杂的SQL查询, 直接获得最后的结果。 但是总是觉得比较慢。 下面做了一个改动,简述如下: * 原来: 纯粹使用SQL查询, 得到最后的结果 * 改进: 使用SQL查询原始数据+Pandas进行数据处理 * 结论: 改进方案的性能提升了300% 原方案: select t2_id, name, col2 from ( select sum(col1) as col1_sum, col2, t2.name, t2_id FROM t1 l…
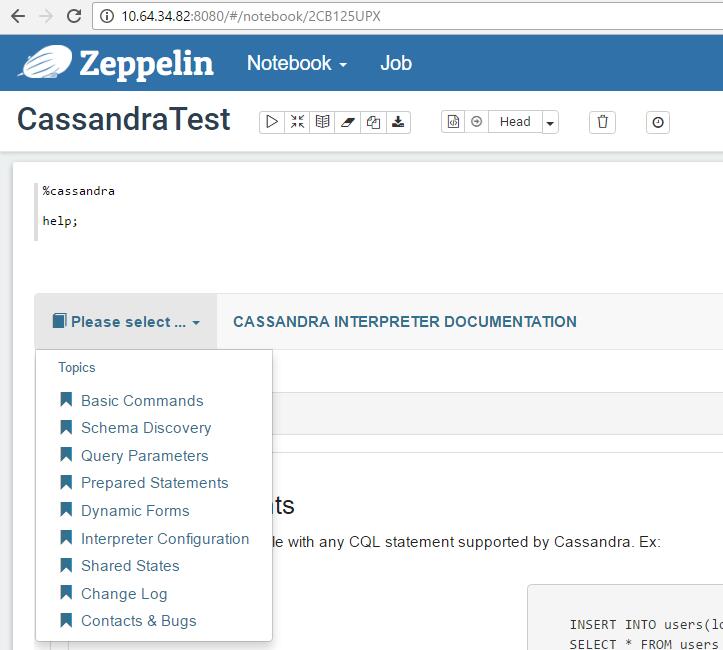
Zepplin 前段时间发布了0.7.0新版本, 在尝鲜的同时, 也在尝试将Zeppelin + Cassandra组合起来使用。 根据官方文档, Cassandra Interpreter 还是做了不少事情的, 说不定比windows版本自带的DevCenter更加好用。 但是在使用之前, 首先得解决Guava冲突的问题。 因为尝试了很多,具体哪一步起作用也不记得了, 下面三部最好都做: 将$ZEPPELIN_HOME/lib 里面的guava-15.0.jar 替换成guava-16.0.1.jar 如果$ZE…

原创声明: 本文为原创文章 如需转载需要在文章最开始显示本文原始链接 为了更好的阅读体验,请回源站查看文章。有任何修改、订正只会在源站体现 最后更新时间:2016年08月28日
原创声明: 本文为原创文章 如需转载需要在文章最开始显示本文原始链接 为了更好的阅读体验,请回源站查看文章。有任何修改、订正只会在源站体现 最后更新时间:2016年08月24日
原创声明: 本文为原创文章 如需转载需要在文章最开始显示本文原始链接 为了更好的阅读体验,请回源站查看文章。有任何修改、订正只会在源站体现

0. 简介 Spark 是一个非常好的计算平台,支持多种语言,同时基于内存的计算速度也非常快。整个开源社区也很活跃。 但是Spark在易用性上面还是有一些美中不足。 对于刚接触的人来说,上手以及环境搭建还是有一些困难。 另外,如果希望将结果绘制成图表分享给别人,还需要很长一段路程。 目前已经有一些解决方案: 【TBD】Jupyter Notebook 使用很广泛,但是看起来主要还是以前ipython-notebook的增强版。 目前笔者对其了解不多 Spark 母公司DataBricks提供的DataBricks …