
原图:http://photo.weibo.com/2687299131/wbphotos/large/mid/4062958860341438/pid/a02cee3bjw1fbndhoa4obj20ckbduu0x

之前尝试使用Spark MLlib 做机器学习,发现不是非常方便,也可能是在使用习惯上面不太适应(相对 python sklearn). 今天尝试使用Spark MLlib 针对Iris数据做一次实践,之后会尝试写一个包装类,将这些步骤简化。 0. 数据准备: 原始的数据以及相应的说明可以到[这里] 下载。 我在这基础之上,增加了header信息。 下载:https://pan.baidu.com/s/1c2d0hpA 如果是可以直接从NFS或者HDFS之类的文件服务里面读csv,会比较方便, 参考下…
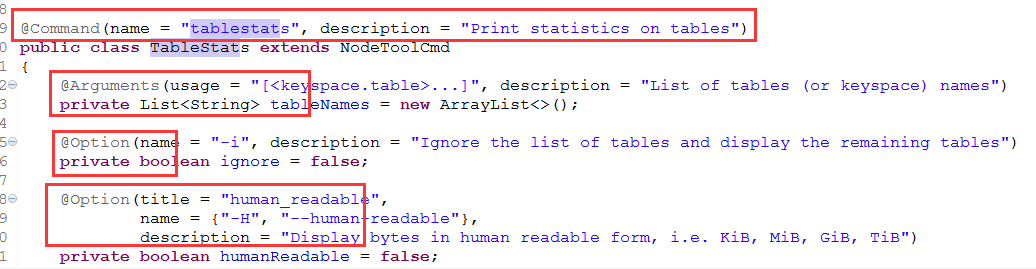
在之前的文章《使用nodetool 进行监控之初步使用》我们提到,新版本的Cassandra Nodetool 支持了 --format / -F 这个参数,可以将内容输出成json或者yaml格式。那么具体是如何实现的呢? 本篇文章的目的就是尝试来阅读以下具体实现的源码。 从哪里入手? 首先https://issues.apache.org/jira/browse/CASSANDRA-5977 。在这个issue之中,附带了patch的实现。从path之中,可以看到commitor首先修改了TableStats的…

文章转自:http://www.jianshu.com/p/21ae5a3037d7 这篇文章写的确实很不错啊,从头到尾把开发一个App的所有环节都讲了,而且讲得基本上还比较清楚。 因为手动转载比较麻烦(图片不能跨域浏览),建议直接到原文去看。
虽然知道得晚了点,但是还是通过Databricks的邮件知道,新版的2.1.0已经发布。 我才刚刚稍微熟悉2.0.X,现在2.1.0已经冒出来~ 官网blog: https://databricks.com/blog/2016/12/29/introducing-apache-spark-2-1.html 那2.1.0 有哪些改进呢? Structured Streaming 已经可以Production了 SQL 功能增强 Mllib for R 增强 原文链接:http://www.flyml.net/2017…
0. 项目背景: 我厂开发了一个App,反应还不错,在app store 上面的好几个区都能拿到工具类的1-3名。 但是在运营上面,一直貌似不够精细。楼主尝试使用机器学习的方法找到对我们影响比较大的App. 所谓“影响比较大”,是指:有哪些App会①带来新用户、②留住老用户、③导致流失用户。 先说说结果: 这是一个比较失败的项目, 因为最后算法的运算结果跟瞎猜没有区别。免得各位看到最后太过失望。。。 源码可以从百度网盘下载:https://pan.baidu.com/s/1gfjzwsj 数据没法奉献出来,抱歉~ …
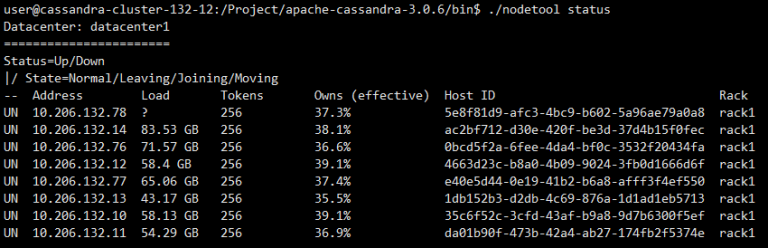
之前的文章《Cassandra自带工具》提到了nodetool的使用,不过当时讲得并不够深入。这篇文章针对监控方向进行一些更深入的介绍。 同时,如果你正好跟我一样没法切换到Enterprise Edition,用好nodetool成为做好Cassandra监控的第一步。 nodetool status 这个命令在之前的文章已经有所介绍。这个是最常用的命令,可以非常明了的看到整个集群的状态。 当你的集群节点不是非常大的时候,使用这个命令非常方便。 nodetool info 查看当前节点的…
整体来说,2016高开低走,建树寥寥~ 所谓高开,是指上半年势头不错,并且我在公司也升了一级,加薪幅度也还可以~ 下半年就是各种不给力跟失败了~ 下面一个一个主要项目过一下~ (1) 在线考试系统 从2015年11月启动,到2016年上半年基本完成。这之中投入了不少时间与精力,到了这两天终于有消息,貌似可以有客户。 希望2017年能真正的开始赚钱,也不在乎多或者少,希望慢慢长大变强,成为一个稳定的资金来源 (2)SkyAidWebService 上半年项目组3个人,黄金搭档。做了不少…
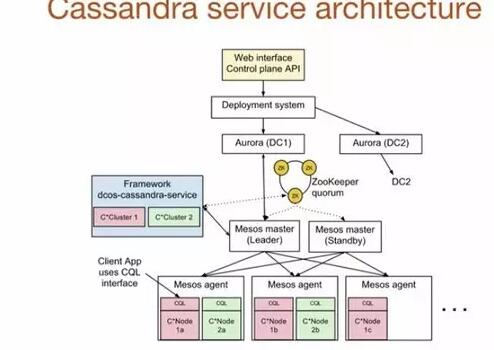
原文链接: http://mp.weixin.qq.com/s/xJhm35IXm_sAPLJ86OwTFA 要点总结: Cassandra运行在Mesos容器之中。使用Mesos在读写延迟上面的影响约在5~10% 写延迟:在裸服务器上平均是0.43ms,而Mesos上是0.48ms。 读延迟:在裸服务器上平均是0.38ms,而在Mesos上是0.44ms。 使用Mesos的好处是,可以面向数据中心的资源编程,控制上要灵活很多 一共2个数据中心,东西海岸各一个,每个300台机器 里面又细分了20个小的集群,这样资源…

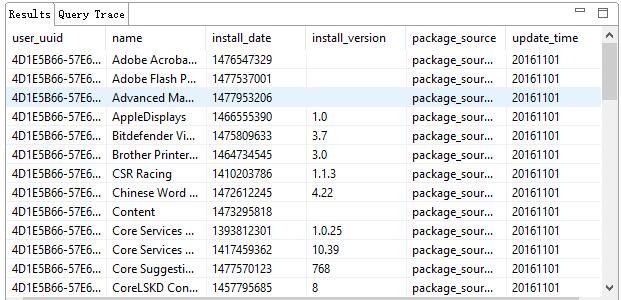
昨天有个同事遇到数据库方面的问题: 他用PostgreSQL记录用户的App的数据,比如一个用户装了100个App,那么在DB之中就有100条记录。当前产品一共有150W这样的用户,那么总共数据集在1.5亿,另外他们使用了uuid-app_name+app_version 三个值作为组合主键,总共约有5亿条记录。 首先他们创建索引之后,每次插入都很慢,另外查询的时候,即使只是按照uuid进行查询,因为数量级已经超过postgreSQL索引的最大容量,只能很麻烦的另外安装插件,通过模糊搜索的方式进行数据…