0. TL;DR
这里只介绍过程,不介绍原理,只做简单分析。
后半段将过一下gensim的simserver是如何调用LSI找到相似文档的。
本文为原创,转载需要注明出处:
http://www.flyml.net/2016/11/11/lsi-doc-sim-gensim-source-code-go-throught/
1.一个简单的语料库
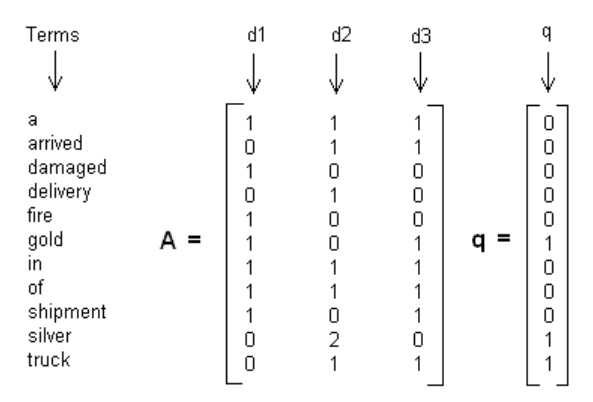
Q: gold silver truck
d1: Shipment of gold damaged in a fire.
d2: Delivery of silver arrived in a silver truck.
d3: Shipment of gold arrived in a truck.
需要解决的问题:Q与哪个文档最接近?
补充说明:
可以使用TFIDF、字符编辑距离等计算文档相似性。具体方法可以参考:
http://chato.cl/2015/data_analysis/01_vector-space-model/vector-space-model.pdf
原文链接:http://www.flyml.net/2016/11/11/lsi-doc-sim-gensim-source-code-go-throught/
2.Term Count Model 矩阵
这种模型比较简单,从TFIDF的角度来说,就是TF了。常见的就是下面这种形式:
word_i 为行,d_j 为一列
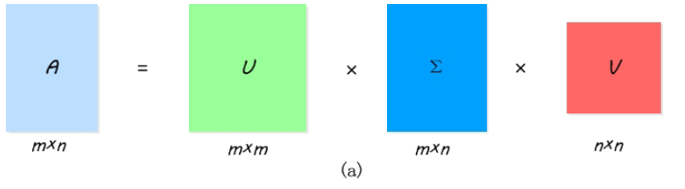
3.使用SVD进行矩阵分解
公式:

计算结果:

注意:矩阵S是一个对角矩阵,并且是按照大小进行了排序
各个矩阵的大小是有讲究的:(下面的仅供参考)
4.开始降维(可选)
如果我们的机器能扛得住原始维度,就不需要下降了。 降维的作用是在精度损失可接受的程度下去掉相对无关的词(并且这些词可能很多很多),从而达到降低资源开销。
假设将维度从3降到2:

计算过程:对于U:取前2列,S:前2x2,V:前2列, VT:前2行
下面的图显示了矩阵是如何被剪裁下来的:
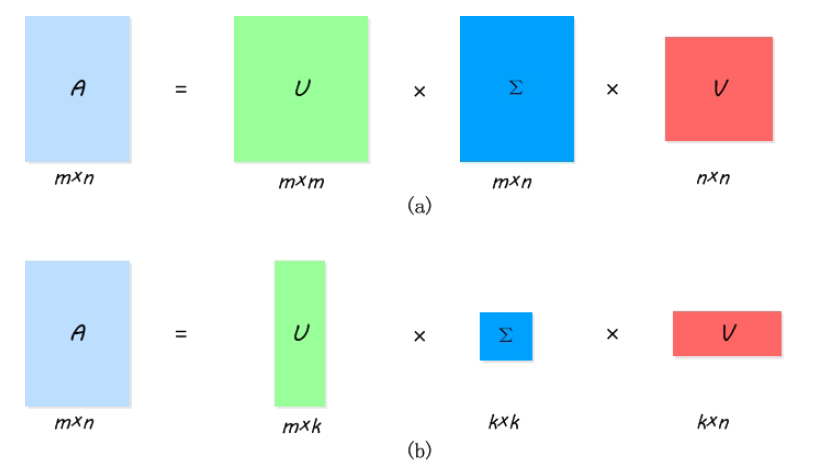
From:https://blog-potatolife.rhcloud.com/?p=132
补充说明:SVD的几何/物理意义?
https://www.zhihu.com/question/22237507
http://blog.sciencenet.cn/blog-696950-699432.html
5. 在(降维的)矩阵之中计算查询语句矩阵(q)
公式: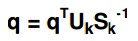
实现:
注意:
- S-1 为S的逆矩阵
- 这一步的q与第一步的q矩阵已经不一样了(不太理解为什么用相同的变量名)
6. 使用余弦相似度计算文档相关性
经过前面的铺垫,终于到我们的目的地了:计算文档相似度

以sim(q,d1)为例,-0.4945与0.6492来自VTk第一列.
在图上画出各个向量,直观比较:
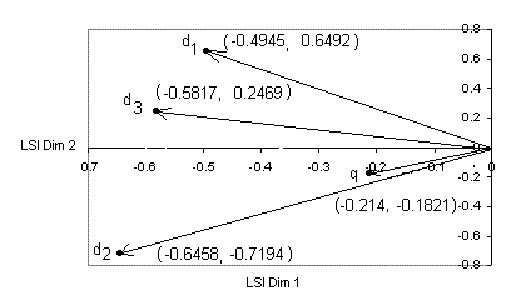
注意: 余弦向量是只看夹角不看长度
原文链接:http://www.flyml.net/2016/11/11/lsi-doc-sim-gensim-source-code-go-throught/
7. 可以进行的一些优化工作:
- 可以尝试将停用词去掉之后再重复进行计算
- 去停用词 + 使用TF-IDF 作为矩阵A的值
8. Gensim的simserver 是如何实现LSI的?
官网地址:http://radimrehurek.com/gensim/simserver.html
- 安装
pip install simserver - 使用
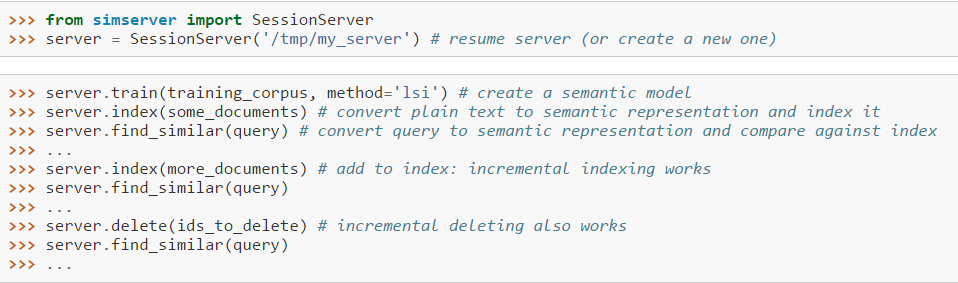
- 实现细节:

可以看到,gensim之中矩阵A已经是TFIDF值了
LSI_TOPICS 已经被hardcode成400了 - LsiModel的参数

上面是LsiModel的构造函数解释一下几个参数的意义:- chunksize: 每次训练多少文档。如果内存不足,可以将chunksize减少,但是消耗的时间更多。
- decay: 如果我们需要忘记老的数据,decay < 1.0
- distributed: 大概是分布式计算。如果启用了,会通过Pyro4进行远程调用~
- onepass: 目前只能是True,False还没有实现,会直接抛出异常
- power_iters: 计算次数。可能进行矩阵分解(SVD),是一个逐步接近的过程,而不是一步到位。计算次数越多,分解出来的矩阵与原始矩阵越接近。
- extra_samples: 目的与power_iters相同(从gensim的解释),原理未知
-
- 他们的mathutils是基于scipy,自己封装了操作。 具体不表~
- 比较有意思的是:k+30,后面的注释是说:这个函数经常会出bug,本来应该返回x列,但是最后会少返回几列~ 于是统统+30,简单粗暴的workaround
- 重要:可以看到k经过了clip_spectrum()之后,数值发生了变化。这个函数主要是看矩阵s然后丢弃掉1%的数据(spectrum, 范围、光谱)
最后两行就是做了降维操作。看看gensim是如何SVD的
我们从304行的Projection进去看看
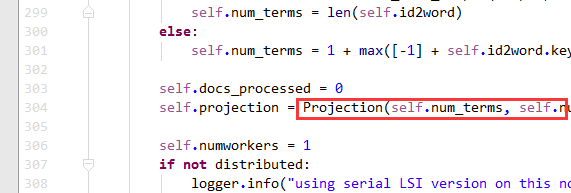 核心步骤:
核心步骤:

本文为原创文章,转载请注明出处原文链接:http://www.flyml.net/2016/11/11/lsi-doc-sim-gensim-source-code-go-throught/


文章评论