
现在网上有一些预先训练好的Word2Vec模型, 比如Glove, Google-News以及我最喜欢的FastText,都有各自使用大数据训练出来的Word2Vec模型。 根据不同的业务, 也可以自己搜集语料库训练Word2Vec. 关于如何使用Keras加上预训练好的W2V模型, 具体可以参考官网教程:Using pre-trained word embeddings in a Keras model 篇幅比较长, 写得“太详细”了。 不过核心就在下面一行代码: (Example Code on …

前言 从这一篇开始, 将开始记录、介绍Keras + TensorFlow组合进行图像以及文本分类。 在实战之前, 首先就是搭建我们的运行环境。 笔者在这里最推荐的还是使用docker进行部署。 在宿主机里面只需要安装cuDNN、NVIDIA-Driver安装好之后,需要TensorFlow就pull一个TensorFlow的镜像。 想要一个Caffe就去pull一个Caffe的镜像。 python2、python3 随便切换。 如果你还没有使用过docker, Google搜索“docker 入门”第一条就是最好…
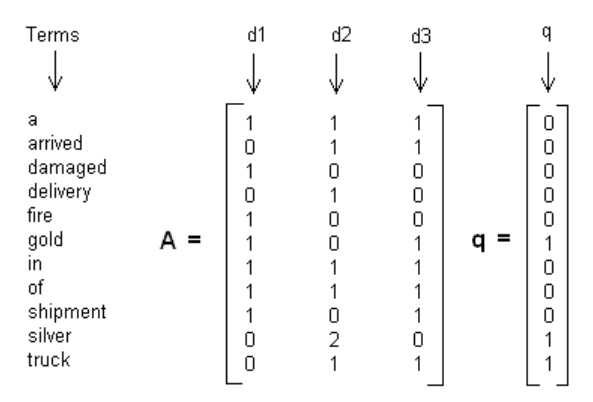
0. TL;DR 本文前半段主要参考:http://www.ce.yildiz.edu.tr/personal/banud/file/1201/latent-semantic-indexing-fast-track-tutorial.pdf 这里只介绍过程,不介绍原理,只做简单分析。 后半段将过一下gensim的simserver是如何调用LSI找到相似文档的。 本文为原创,转载需要注明出处: http://www.flyml.net/2016/11/11/lsi-doc-sim-gensim-source-cod…
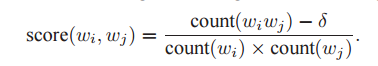
1. phrase公式基本介绍 在将语料库喂给word2vec进行训练之前,我们首先需要将其中一些常见的词组组合起来变成一个单词,这样对训练的精度会非常有帮助。 word2vec的作者采用的是下面的公式: wi,wj : 第i跟第j个单词 (实际上我认为j=i+1, 不需要用两个下标) δ 是一个调节参数。 (由于字体问题,公式截图跟文字里面的delta看起来不完全一样) 在gensim之中,这个公式稍有不同: score = ( cnt(a, b) - min_count ) * N / (cn…

0. 引言 上周五在公司使用gensim的word2vec实验了一次“文档相似性”计算。匹配出来的结果惨不忍睹,可以用“天马行空”来形容。这就是对word2vec不了解的情况下做调包侠的下场。。。 下面是笔者对word2vec的一些初步了解与效果反思。 本文为原创。 转载需要注明出处:http://www.flyml.net/2016/11/07/word2vec-basic-understanding/ 1. 为什么学习w2v? 简单的说,我们在声音与图像领域,深度学习都取得了令人瞩目的成就,其中一个重要的原因,…

原创声明: 本文为原创文章 如需转载需要在文章最开始显示本文原始链接 为了更好的阅读体验,请回源站查看文章。有任何修改、订正只会在源站体现