0. 引言
上周五在公司使用gensim的word2vec实验了一次“文档相似性”计算。匹配出来的结果惨不忍睹,可以用“天马行空”来形容。这就是对word2vec不了解的情况下做调包侠的下场。。。
下面是笔者对word2vec的一些初步了解与效果反思。
本文为原创。
转载需要注明出处:http://www.flyml.net/2016/11/07/word2vec-basic-understanding/
1. 为什么学习w2v?
简单的说,我们在声音与图像领域,深度学习都取得了令人瞩目的成就,其中一个重要的原因,就是DL在这些领域找到了一些“最基础的元素”。而文字、语言方面,可以认为词向量就是这“最基本的元素”。

同时w2v训练出来的词向量还能作为各种NN,比如CNN、RNN的输入。
注意:词向量并不是word2vec的首创,word2vec只是在训练模型的方法上进行了创新(使得需要更少的参数、更快的速度、更好的效果)。最原始的VSM(向量空间模型)可能是词向量的首创。
2. 关于vector的一些语义解释
借用来自TensorFlow官网的一幅介绍图片:
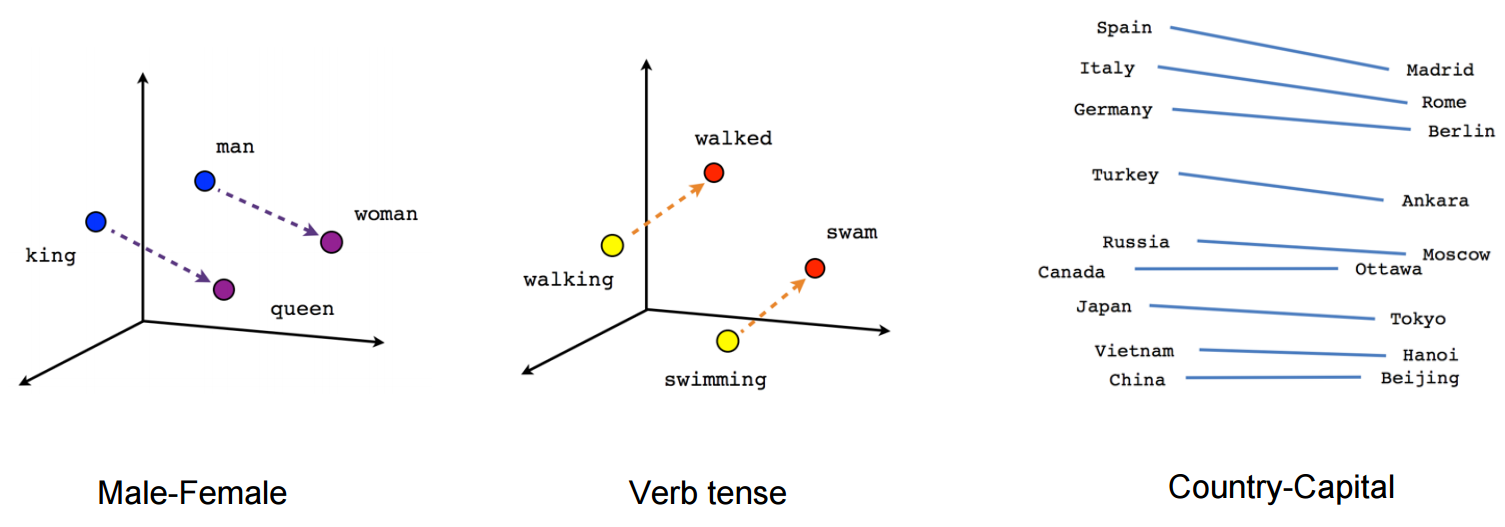
我一开始没有意识到这一个关键点:
在每一幅图里面,向量都相等或者接近相等。
并且需要注意前两幅图都有画出箭头。 这就代表了他们的语义。同时复习一下向量相减:
比如从king指向queen的向量:king --> queen = vector(queen) - vector(king)
可以这么来理解vector(queen) - vector(king) :
queen减去king的属性之后剩余的属性,跟woman减去man之后剩余的属性相等。
因此有等式: queen - king = woman - man (粗黑体表示向量)
下面是gensim加载了google训练的w2v模型之后的计算结果:
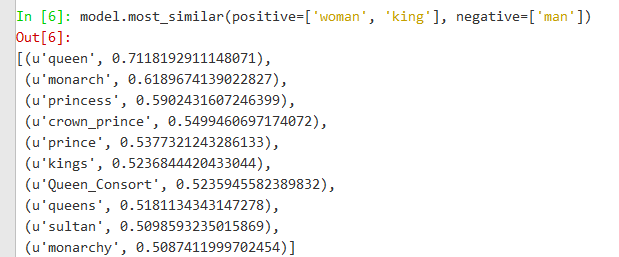
出一个小题目供大家思考:shorter - short + longer = ?
3. word2vec的适用场景
4. 上下文
5.那么多vector,全部搜索一遍?
6. 说点实际的: 为什么上次效果那么差?
本文为原创文章,转载请注明出处原文链接:http://www.flyml.net/2016/11/07/word2vec-basic-understanding/


文章评论