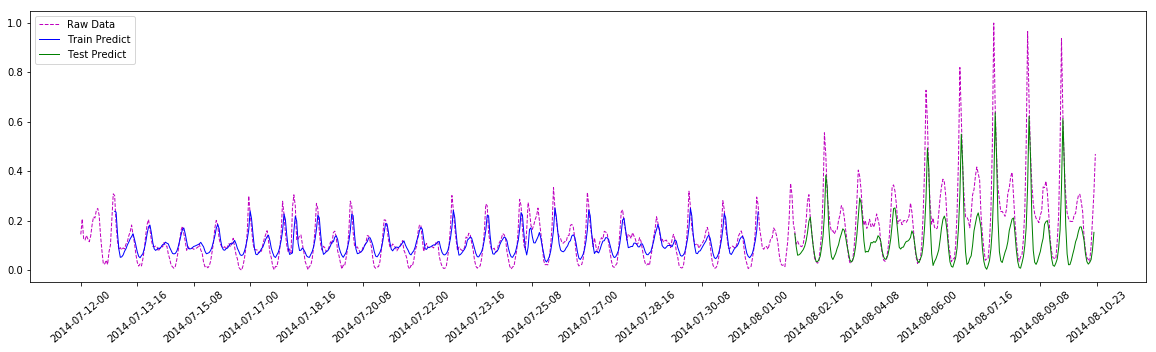
本次命题: 数值预测 上一篇文章我们的小题目是使用LSTM预测字符顺序的下一个字符。 命题虽然简单, 可是实际上应用范围也很广。 比如输入法里面, 就一定会用到相关的技术。 只不过不一定是LSTM, 肯定也不止一维特征。这次这个命题相对来说, 比较实际一些:从历史预测监控数据预测即将来临的监控指标的数值。 比如下图就是本站在友盟上面的监控数据。 最右边的虚线部分就是友盟进行的预测的数值: 本文代码特别鸣谢:https://blog.csdn.net/aliceyangxi1987/article/details/7…
想解决的问题 一个通用的模型, 希望能适用所有的日志. 比如常见的System Event Log. 尝试从这些大量的日志之中找到异常\不规则的地方 主要架构 分为3个模型: Log Key Anomaly Detection model 主要是根据生成的Log Key, 使用LSTM进行判断下一个Log Key是否是异常信息. 主要是使用了NLP的思想. 个人感觉这一块是DeepLog最有启发的一个模型. Workflows 主要是能识别出并行的日志. 但是具体怎么用, 没有(在Youtube视频上面)详细说明 …

之前在看Keras Example的时候, 发现对于NLP相关的任务使用的NN都非常浅。 没有很严谨的去数, 但是基本上都是一两层网路就结束了。 具体可以参考Keras Example 之中IMDB相关的代码。 当然, 效果也不差。 一直对这一块很奇怪。 偶然从知乎上面的一篇文章获得解答。 参考: 如何评价Word2Vec作者提出的fastText算法?深度学习是否在文本分类等简单任务上没有优势? 简要观点: 项亮: 文本分类基本还是个偏线性的问题。多层的网络相对单层的没有太多优势。但这不是说多层的没用,而是单层的…

现在网上有一些预先训练好的Word2Vec模型, 比如Glove, Google-News以及我最喜欢的FastText,都有各自使用大数据训练出来的Word2Vec模型。 根据不同的业务, 也可以自己搜集语料库训练Word2Vec. 关于如何使用Keras加上预训练好的W2V模型, 具体可以参考官网教程:Using pre-trained word embeddings in a Keras model 篇幅比较长, 写得“太详细”了。 不过核心就在下面一行代码: (Example Code on …

前言 从这一篇开始, 将开始记录、介绍Keras + TensorFlow组合进行图像以及文本分类。 在实战之前, 首先就是搭建我们的运行环境。 笔者在这里最推荐的还是使用docker进行部署。 在宿主机里面只需要安装cuDNN、NVIDIA-Driver安装好之后,需要TensorFlow就pull一个TensorFlow的镜像。 想要一个Caffe就去pull一个Caffe的镜像。 python2、python3 随便切换。 如果你还没有使用过docker, Google搜索“docker 入门”第一条就是最好…