
我们知道,Cassandra这种NoSQL数据库,天生无法执行join的操作。 但是如果你手上刚好有一个Spark集群,那么就方便很多了。我们可以在Spark SQL之中进行join的操作。 本文基于Spark 2.x 进行操作。2.0以后,我们不再需要单独的定义JavaSparkContext / SparkConf 等对象,只需直接定义一个SparkSession即可。同时我们可以统一使用Dataset来对数据进行操作,在易用性、性能上面都很不错。 下面是链接Spark与Cassandra的相关代码: [cra…

在python之中,读文件是一个很简单的事情。 直接 open("filename")就可以了。但是python2之中对CJK三种语言却处理得很蛋疼。 特别是在读取CJK语言的文件的时候,一种比较保险的强制使用某种编码的方法是使用codecs类库。 比如: [crayon-69a24886d2315100679288/] 否则,可能出现一些奇奇怪怪的错误~
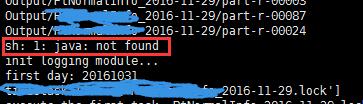
虽然称之为“坑”,但是主要还是我自己对立面的道道不太了解所致。 背景介绍: 首先有一个python脚本,这个python首先会执行一些linux的命令,比如解压文件、复制文件等等,完成之后会通过java -jar的方式调用某一个jar包做一些操作。 原文来源:http://www.flyml.net/2016/11/30/crontab-java-not-found/ 问题表现: 每次手动执行这个python脚本运行,程序工作的很好,但是如果是通过crontab的方式来运行,就会发现程序只执行了,但是java应该做…
花钱的年华 http://calvin1978.blogcn.com/ PS: 可能要翻墙,因为这个域名直接访问看起来已经被劫持了~ PS2 : 有人说打开没样式,我加个截图:
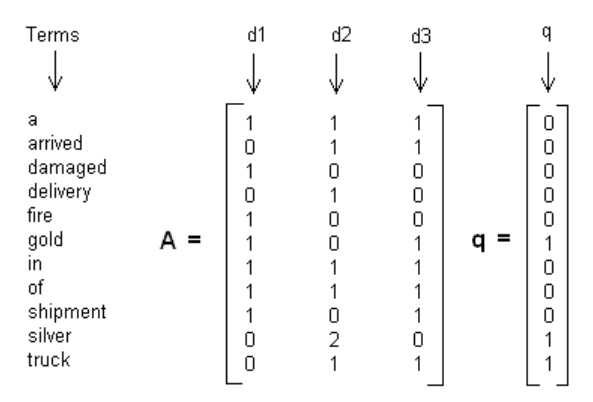
0. TL;DR 本文前半段主要参考:http://www.ce.yildiz.edu.tr/personal/banud/file/1201/latent-semantic-indexing-fast-track-tutorial.pdf 这里只介绍过程,不介绍原理,只做简单分析。 后半段将过一下gensim的simserver是如何调用LSI找到相似文档的。 本文为原创,转载需要注明出处: http://www.flyml.net/2016/11/11/lsi-doc-sim-gensim-source-cod…
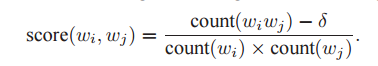
1. phrase公式基本介绍 在将语料库喂给word2vec进行训练之前,我们首先需要将其中一些常见的词组组合起来变成一个单词,这样对训练的精度会非常有帮助。 word2vec的作者采用的是下面的公式: wi,wj : 第i跟第j个单词 (实际上我认为j=i+1, 不需要用两个下标) δ 是一个调节参数。 (由于字体问题,公式截图跟文字里面的delta看起来不完全一样) 在gensim之中,这个公式稍有不同: score = ( cnt(a, b) - min_count ) * N / (cn…
在阅读Google的免费深度学习课程的练习代码的时候,看到下面一段代码: [crayon-69a24886d3148567371171/] 注意第17行,第一个变量居然是一个下划线! 在查阅了一些资料之后,有人是这么描述单个下划线的使用场景: 在交互式的时候,保持上一次执行的结果 没看懂。原文如下: To hold the result of the last executed statement in an interactive interpreter session. This precedent was s…

0. 引言 上周五在公司使用gensim的word2vec实验了一次“文档相似性”计算。匹配出来的结果惨不忍睹,可以用“天马行空”来形容。这就是对word2vec不了解的情况下做调包侠的下场。。。 下面是笔者对word2vec的一些初步了解与效果反思。 本文为原创。 转载需要注明出处:http://www.flyml.net/2016/11/07/word2vec-basic-understanding/ 1. 为什么学习w2v? 简单的说,我们在声音与图像领域,深度学习都取得了令人瞩目的成就,其中一个重要的原因,…
对Cassandra的架构做了一些了解,没有深入代码级别,有一些细枝末节也没有完全摸清楚。不过在大致流程上,基本上理解。在此做个阶段性的小结。 具体请看PDF 本文为原创文章,转载请注明出处 原文链接:http://www.flyml.net/2016/11/07/cassandra-tutorial-architecture/