目前很火的芝士超人、百万英雄等等,已经有不少人做了答题辅助。 比如: https://github.com/Skyexu/TopSup https://github.com/rrdssfgcs/wenda-helper 但是个人感觉,他们都缺少了最后一公里: 需要人手工触发。 我们目前做的这个事情,就是尝试把最后一公里简化, 你只需要 调用我们的API 或者基于我们的源码与模型, 在本地搭建一个你自己的API, 之后只需要不停的执行截图并调用API获取结果就可以了。 项目地址:https://github.com/…
论文链接: http://aclweb.org/anthology/D17-1312 这一篇论文, 主要想解决的问题是在一个新的领域, 当现有的语料不足够大的时候, 如何充分利用之前已经有的一些语料增强当前领域的词向量模型。 具体算法并不复杂, 不过感觉距离实用还是有一些距离: 首先需要原始语料,而不是原始语料训练出来的模型 因为需要得到一个词在原始语料的概率分布 还需要一个词同时在两个语料之中同时出现。 可是目前的情况是, 我们只有Google / Facebook / Stanford 等发布的大规模训练出来的…

引言: 因为在工作之中接触到NER,并且可以有需要NER的地方。在此总结一些相关资料与自己的理解。 什么是命名实体识别 此段原文: http://blog.csdn.net/dvstream/article/details/17784293 命名实体识别(Named Entity Recognition, NER),又称作“专名识别”,主要任务是识别出文本中的人名、地名等专有名称和有意义的时间、日期等数量短语并加以归类。对很多文本挖掘任务来说,命名实体识别系统是重要的组成部分:一方面,命名实体识别可以帮助识别未登录…
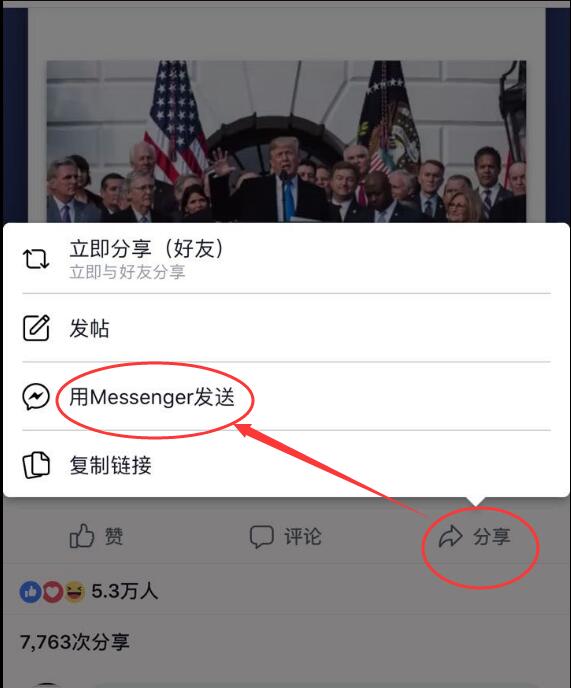
Introduction This simple bot is useful to help to download facebook videos on mobile phone. Biggest Advantage: No Privacy Leak Risk Facebook Page: https://www.facebook.com/XVideoHunter Messenger Link: http://m.me/XVideoHunter Too many apps, why need this? This…
简介 这个小机器人的作用很简单, 帮你【在手机上】获取Facebook上面Video的下载链接。 重点: 【不会泄露隐私!】 已经很多人做啦,为什么还要再做一个? 目前这种方式还是比较新颖的。 Google Play/App Store 上面的手机App, 都需要你使用自己的账号登录他们的App。 他们的App会干神马事情,我是真的不知道~ 浏览器插件。 这种方式,插件还是能看到你的Facebook的一些隐私内容。手机上对插件支持比较好的, 貌似就是Firefox了。 第三方网站 这种方式挺好的, 但是只合适PC之…

荷兰航空 KLM Royal Dutch Airlines - 提醒客户飞机状态 点评: 感觉这个Bot还挺实用的。 Facebook针对航班还有特殊的消息模板。 看了一下, 自定义的地方也挺强的。 如果国内能访问的话, 其实可以改造成高铁的提醒。 Whole Foods Market - 智能食谱 Messenger链接: https://www.messenger.com/t/24922591487 开场白: 简单测试了一下: I love to eat some cake 点评: 感觉还是关键词匹配。我本身对…

之前在看Keras Example的时候, 发现对于NLP相关的任务使用的NN都非常浅。 没有很严谨的去数, 但是基本上都是一两层网路就结束了。 具体可以参考Keras Example 之中IMDB相关的代码。 当然, 效果也不差。 一直对这一块很奇怪。 偶然从知乎上面的一篇文章获得解答。 参考: 如何评价Word2Vec作者提出的fastText算法?深度学习是否在文本分类等简单任务上没有优势? 简要观点: 项亮: 文本分类基本还是个偏线性的问题。多层的网络相对单层的没有太多优势。但这不是说多层的没用,而是单层的…

现在网上有一些预先训练好的Word2Vec模型, 比如Glove, Google-News以及我最喜欢的FastText,都有各自使用大数据训练出来的Word2Vec模型。 根据不同的业务, 也可以自己搜集语料库训练Word2Vec. 关于如何使用Keras加上预训练好的W2V模型, 具体可以参考官网教程:Using pre-trained word embeddings in a Keras model 篇幅比较长, 写得“太详细”了。 不过核心就在下面一行代码: (Example Code on …

前言 从这一篇开始, 将开始记录、介绍Keras + TensorFlow组合进行图像以及文本分类。 在实战之前, 首先就是搭建我们的运行环境。 笔者在这里最推荐的还是使用docker进行部署。 在宿主机里面只需要安装cuDNN、NVIDIA-Driver安装好之后,需要TensorFlow就pull一个TensorFlow的镜像。 想要一个Caffe就去pull一个Caffe的镜像。 python2、python3 随便切换。 如果你还没有使用过docker, Google搜索“docker 入门”第一条就是最好…

之前尝试使用Spark MLlib 做机器学习,发现不是非常方便,也可能是在使用习惯上面不太适应(相对 python sklearn). 今天尝试使用Spark MLlib 针对Iris数据做一次实践,之后会尝试写一个包装类,将这些步骤简化。 0. 数据准备: 原始的数据以及相应的说明可以到[这里] 下载。 我在这基础之上,增加了header信息。 下载:https://pan.baidu.com/s/1c2d0hpA 如果是可以直接从NFS或者HDFS之类的文件服务里面读csv,会比较方便, 参考下…