虽然知道得晚了点,但是还是通过Databricks的邮件知道,新版的2.1.0已经发布。 我才刚刚稍微熟悉2.0.X,现在2.1.0已经冒出来~ 官网blog: https://databricks.com/blog/2016/12/29/introducing-apache-spark-2-1.html 那2.1.0 有哪些改进呢? Structured Streaming 已经可以Production了 SQL 功能增强 Mllib for R 增强 原文链接:http://www.flyml.net/2017…
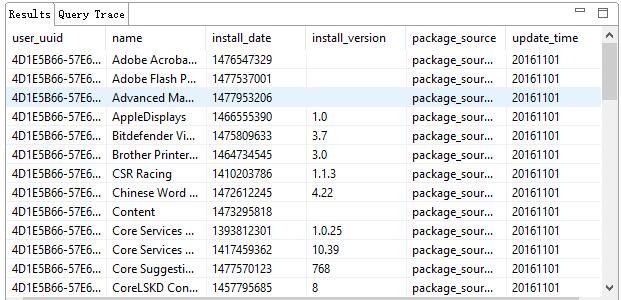
0. 项目背景: 我厂开发了一个App,反应还不错,在app store 上面的好几个区都能拿到工具类的1-3名。 但是在运营上面,一直貌似不够精细。楼主尝试使用机器学习的方法找到对我们影响比较大的App. 所谓“影响比较大”,是指:有哪些App会①带来新用户、②留住老用户、③导致流失用户。 先说说结果: 这是一个比较失败的项目, 因为最后算法的运算结果跟瞎猜没有区别。免得各位看到最后太过失望。。。 源码可以从百度网盘下载:https://pan.baidu.com/s/1gfjzwsj 数据没法奉献出来,抱歉~ …
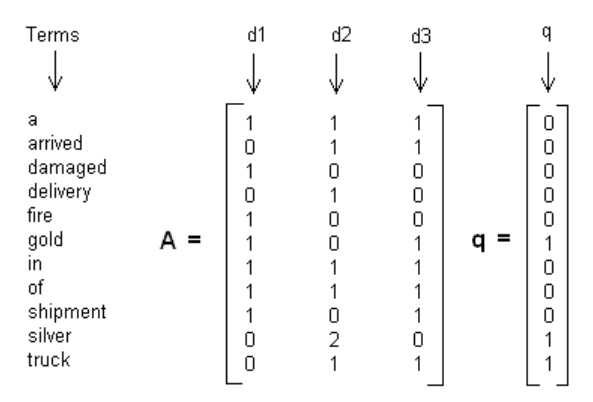
0. TL;DR 本文前半段主要参考:http://www.ce.yildiz.edu.tr/personal/banud/file/1201/latent-semantic-indexing-fast-track-tutorial.pdf 这里只介绍过程,不介绍原理,只做简单分析。 后半段将过一下gensim的simserver是如何调用LSI找到相似文档的。 本文为原创,转载需要注明出处: http://www.flyml.net/2016/11/11/lsi-doc-sim-gensim-source-cod…
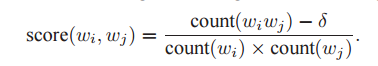
1. phrase公式基本介绍 在将语料库喂给word2vec进行训练之前,我们首先需要将其中一些常见的词组组合起来变成一个单词,这样对训练的精度会非常有帮助。 word2vec的作者采用的是下面的公式: wi,wj : 第i跟第j个单词 (实际上我认为j=i+1, 不需要用两个下标) δ 是一个调节参数。 (由于字体问题,公式截图跟文字里面的delta看起来不完全一样) 在gensim之中,这个公式稍有不同: score = ( cnt(a, b) - min_count ) * N / (cn…

0. 引言 上周五在公司使用gensim的word2vec实验了一次“文档相似性”计算。匹配出来的结果惨不忍睹,可以用“天马行空”来形容。这就是对word2vec不了解的情况下做调包侠的下场。。。 下面是笔者对word2vec的一些初步了解与效果反思。 本文为原创。 转载需要注明出处:http://www.flyml.net/2016/11/07/word2vec-basic-understanding/ 1. 为什么学习w2v? 简单的说,我们在声音与图像领域,深度学习都取得了令人瞩目的成就,其中一个重要的原因,…

今天发现Kaggle上有一个新的机器学习比赛,主题是RedHat 用户商业价值预测。 参赛地址: https://www.kaggle.com/c/predicting-red-hat-business-value 比赛还剩24天,差不多过了一半。后面如果实力足够,还是有机会拿奖。 奖金一共5W美刀!按照现在差不多1:6.6的比例来计算,差不多有33W人民币呢! 而且这次比赛的数据量也不是很大,单机基本上就可以搞定。 File Name Available Formats people.csv .zi…
原创声明: 本文为原创文章 如需转载需要在文章最开始显示本文原始链接 为了更好的阅读体验,请回源站查看文章。有任何修改、订正只会在源站体现
原创声明: 本文为原创文章 如需转载需要在文章最开始显示本文原始链接 为了更好的阅读体验,请回源站查看文章。有任何修改、订正只会在源站体现 在机器学习中,通常我们要衡量一个分类器分类结果的好坏,用于评价并改进分类器。本文将整理总结常见的度量指标并举例说明该指标在sklean中是如何实现的。 1. 准确率 所有测试样本中,被正确分类的比例。当然这个比例越高越好。最大值为1。在sklean中的计算也非常简单 [crayon-6a57009cea129537706675/] 1.1 混淆矩阵 为了更加精细的…
最近在做ChatBot,看了一些很惊艳的论文,比如: A Neural Conversational Model (v3) 根据论文描述,Chatbot甚至能给人debug为什么不能上网之类的技术问题。 OMG! 摘录一些对话: Machine: hi Human: hi Machine: could you please let me know what is the operating system you are using? Human: linux Machine: ok this is the issu…